-
CV#1 A ConvNet for the 2020s 논문 리뷰REVIEW 2022. 4. 26. 23:08반응형
논문 링크 : https://arxiv.org/abs/2201.03545
회사에서의 업무가 Computer Vision의 Document Analysis 쪽을 하게 되면서, 모델 성능 개선을 위해 찾던 중 읽은 논문을 요약하여 정리하려고 한다. 이 논문의 주요 포인트는 CV 분야에서 Transformer 기반의 모델이 좋은 성능을 보이는데, 이것이 Transformer가 CNN 보다 좋음을 의미하지 않는다는 것을 말하려고 하는 것이다. 현재 Image Classification 에서는 VIT 모델이, Semantic Segmentation 등의 모델에서는 hierarchical Transformers를 사용한 Swin Transformers 모델이 가장 좋은 성능을 보인다. 본 논문에서는 이 모델들에서 사용한 학습 전략과 트릭 등을 CNN 계열의 모델(Resnet)에 적용하면 높은 정확도를 얻을수 있음을 이야기한다. 즉, Resnet 모델을 Modern화 시키는 것이다.
아래의 그래프는 성능과 GFLOPS를 나타내는데, 기본 ResNet에 다양한 전략을 추가할때 성능과 GFLOPs에 대한 변화를 보여준다.

본 논문에서는 아래의 총 6가지의 방안을 사용한다.
Modernizing a ConvNet: a Roadmap
- Macro design
- ResNeXt
- inverted bottleneck
- large kernel size
- Various layer-wise micro designs
Training techniques
VIT는 adamW와 같은 것을 cv에 소개했음. 즉 ResNet-50/200을 VIT의 방식을 통하여 학습
- DeiT 와 Swin Transformer의 recipe 를 사용하였음. 300 epoch, adamW 등(아래에 자세히 정리)
- 데이터 증강 기법 : mixup, cutmix, radnAugment, random erasing, regularization schme, stochastic depth, label smoothing 사용.
- 위의 방식과 hyper parameter 수정만으로도 2.7%의 성능 향상.

Macro Design
- Changing stage compute ratio
Swin-T는 Stage compute ratio 1:1:3:1로, Large 에서는 1:1:9:1로 이에 따라서 ResNet-50에서 (3, 4, 6, 3)인걸 (3,3,9,3)으로 사용. → 0.6 증가
- Changing stem to “Patchify”
4x4 filter size에 stride 4를 주어 convolution을 수행하였고 이는 Non-overlapping convolution 이 Swim-T의 stem과 동일한 역할을 하도록 개선.
ResNeXt-ify
- 가이드를 use more groups, expand width 로 잡고 구성. 3 x 3 conv layer를 bottleneck block으로 만듬.
- 본 논문에서는 depthwise convolution(by mobilenet) 를 사용하여 채널수와 동일한 group 갯수로 만듬.
- depthwise conv 의 weighted sum= self-attention과 같은 의미로 볼수 있다. 이후 , 1 x 1 conv가 채널에 대한 혼합을 수행. Swit-T와 채널수를 비슷하게 하기위해 채널을 96으로 설정.
Inverted Bottleneck

- a → b로 바꿔서 설계, flop이 늘어나지만, 전체적으로는 줄어듬. 최종 아웃이 96임.
- 최종적으로는 C로 변경, 계산량 더 감소. 자세한건 아래에 이유 작성되어있음.
Large kernel size
- 기존 표준은 (VGGNet) 3 x 3 커널 사이즈로 구성, 이것은 GPU에서 효율적인 연산 가능. 하지만, Swin-T에서 self-attention block의 window가 최소 7x7로 구성된것을 참고하여 커널 사이즈를 키움.
- Moving up depthwise conv layer
큰 커널을 쓰기위한 전제조건으로 위의 inverted bottolneck의 구조를 위의 (c)와 같은 형태로 변경해야함. 이는 연산량의 감소를 가지고 오게됨. - Increasing the kernel size.
3,5,7,9,11을 실험적으로 해봤지만, 7x7이 가장 좋은 성능을 보임.
Micro Design
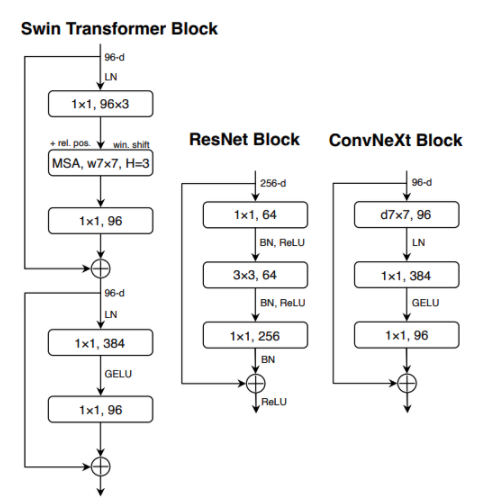
- Replacing ReLU with GELU
Transformer 논문들에서 효율적이라고 사용하고 있음. 하지만, 정확도에 변동 없음 - Fewer activation functions
Transformer 는 Resnet보다 더 적은 activation function을 사용하고 있음. 하지만 conv는 1x1 vonv와 activation을 붙이는 것이 일반적. 우리는 2개의 1x1레이어 중의 1개의 activation을 삭제, 즉 1개의 block당 1개의 activation fucntion 사용. - Fewer normalization layers
Transformer는 적은 normalization layer 사용, Resnet block은 3개의 BN 레이어를 사용하지만, 이를 1개만 남기고 삭제. 삭제 규칙은 BN을 1x1 layer에서는 사용하지 않음. - Substituting BN with LN
BN은 convnet에서 수렴을 잘하게 하면서, 과적합을 줄인다. 그러나 많은 복잡성을 가지고 오게됨, 이는 모델 성능에 안좋은 영향력을 줌. 그래서 transformer에서 사용하는 Layer Normalization (LN)을 적용 - Separate downsampling layers
기존에는 3x3, stride 2의 conv layer를 사용, Swin-T에서는 stage 사이에 downsampling을 위한 블럭을 추가함. → 2 x 2, stride 2의 layer. 위와 동일하게, stage와 downsampling layer가 반복. 추가적으로 downsampling에는 normalization layer를 추가하면 훈련 안정화에 도움을 줌.
결론
2020년대에 와서 비전 트랜스포머, 특히 Swin 트랜스포머와 같은 계층적 트랜스포머가 일반 CNN 기반의 백본 모델의 성능을 추월했다. Vision Transformer가 ConvNet보다 더 정확하고 효율적이며 확장 가능하다는 믿음이 널리 퍼져 있습니다. 이 논문에서는 표준 ConvNets의 단순성과 효율성을 유지하면서 여러 컴퓨터 비전 벤치마크에서 Transformer 기반 모델과 경쟁할수 있는 CNN기반의 ConvNeXts. ConvNeXt 모델 자체가 완전히 새로운 것은 아니지만, 많은 디자인 선택이 지난 10년 동안 개별적으로 적용한 것을 통합하여 좋은 결과를 만들어 내었고 이를 통해 CV에 convolution 의 중요성을 증명하려 한다.
반응형'REVIEW' 카테고리의 다른 글
#LLM+추천시스템 Large Language Models meet Collaborative Filtering: An EfficientAll-round LLM-based Recommender System 논문 리뷰 (2) 2024.07.19 지식 그래프를 Ai에 활용하기 (0) 2022.03.21 추천 #2) 컨텐츠 기반 모델 - 유사도 함수, TF-IDF (0) 2021.08.08 추천#1) 룰 기반의 연관 분석, Apriori, FP-Growth (0) 2021.08.07 KG#3 ) Translation Model for KC (TransE, TransR 리뷰) (0) 2021.04.11