-
추천 #2) 컨텐츠 기반 모델 - 유사도 함수, TF-IDFREVIEW 2021. 8. 8. 22:51반응형
이 글은 유튜브의 T아카데미에 공개되어있는 추천 시스템 분석 입문하기를 기반으로 작성 되었습니다.
컨텐츠 기반 모델은 사용자가 이전에 구매한 상품 중에서 좋아하는 상품과 유사한 상품을 추천하는 알고리즘이다. 이를 찾는 방법은 아이템을 벡터 형태로 표현하여, 해당 아이템과 유사한 벡터를 가진 다른 아이템을 찾는 방식을 사용한다. 컨텐츠 기반 모델은 아래와 같은 방식으로 진행한다.

유사도 함수는 벡터로 표현된 각 상품간의 관계를 계산하기 위해서 필요한데, 굉장히 다양한 방법이 존재하지만 4가지 방식을 설명한다.
1. 유클리디안 유사도
문서간의 유사도를 계산하기 위한 방식으로 여기서 문서는 지난 편에서 이야기한 거래내역과 같다고 보면 된다. 유클리디안 유사도는 유클리디안 거리의 역을 취한 것으로, 여기서 1e-05는 분모가 0이 되는 것을 방지하는 것이다. 계산하기 쉬운 장점을 가지고 있고, p,q의 분포가 다르거나 범위가 다르면 계산이 불가능 하다.

2. 코사인 유사도
문서간의 유사도를 계산하기 위한 방식으로 얼마 만큼의 코사인 세타를 가지고 있는가를 계산하는 것이다. 0~1로 표현되고, 두 벡터간의 거리를 구한다고 볼수 있다. 문서 내에서 단어의 등장 비율을 활용하기에 크기가 중요한 경우에는 잘 동작하지 않다.

3. 피어슨 유사도
상관관계 계산할때 일반적으로 사용하는 방식이다.

4. 자카드 유사도
집합에서 얼마많큼의 결합된 부분이 있는지로 계산하는 방식이다.
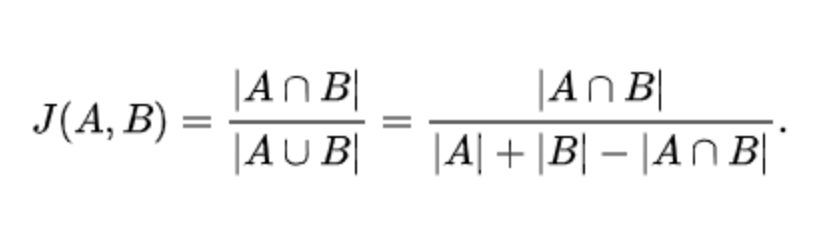
TF-IDF
- TF 단어빈도 : 특정 문서 내에서 특정 단어가 얼마나 자주 등장하는가.
- DF 역문서 빈도 : 전체 문서에서 특정 단어가 얼마나 자주 등장하는가.
TF-IDF의 정의 : 위의 두개의 빈도를 통해서 다른 문서에서는 등장하지 않지만 특정 문서에서만 자주 등장하는 단어를 찾아서 각 단어의 가중치를 만들어내는 방식이다. TF-IDF 는 결과적으로 빈도수 기반의 단어들의 벡터를 생성한다고 보면 된다. 그래서 Counter Vectorizer 방법이라 표현한다.
실제적으로 알고리즘의 동작모습은 아래를 통해서 쉽게 볼수 있는데, 결과적으로 TF는 문서 내에서 단어를 카운트하고 DF는 전체에서 단어를 카운트한다. 4개의 문서가 있다고 보자.
- 문서 1 : 먹고 싶은 사과
- 문서 2 : 먹고 싶은 바나나
- 문서 3 : 길고 노란 바나나 바나나
- 문서 4 : 저는 과일이 좋아요
각 문서의 TF는 아래와 같다. TF의 계산의 경우 아래와 같이 사용한 빈도수를 사용해도 되고 이를 개선하는 방식으로 불린 빈도, 로그 스케일 빈도, 증가 빈도 등도 사용한다.
문서 과일이 길고 노란 먹고 바나나 사과 싶은 저는 좋아요 문서 1 0 0 0 1 0 1 1 0 0 문서 2 0 0 0 1 1 0 1 0 0 문서 3 0 1 1 0 2 0 0 0 0 문서 4 1 0 0 0 0 0 0 1 1 DF는 아래와 같다. DF를 통해서 IDF를 아래의 수식을 통해서 계산하게 되고, 이를 TF와 곱하면 각 항목에 대한 TF-IDF 벡터를 구하게 된다.
과일이 길고 노란 먹고 바나나 사과 싶은 저는 좋아요 총합 1 1 1 2 3 1 2 1 1  반응형
반응형'REVIEW' 카테고리의 다른 글
CV#1 A ConvNet for the 2020s 논문 리뷰 (0) 2022.04.26 지식 그래프를 Ai에 활용하기 (0) 2022.03.21 추천#1) 룰 기반의 연관 분석, Apriori, FP-Growth (0) 2021.08.07 KG#3 ) Translation Model for KC (TransE, TransR 리뷰) (0) 2021.04.11 KG#2) Knowledge Completion 개념 및 주요 TASK (0) 2020.10.04